
按【Ctrl+D】或拖动【 小墨鹰LOGO】到书签栏,收藏本站!
一、小墨鹰简介
二、新版视频教程
三、新手入门
四、微信公众号早报
五、手机版编辑器
六、功能详细介绍
七、基础排版技巧
八、常见问题解答
九、微信公众号扫盲
十、高级功能详细介绍
十一、进阶排版技巧
十二、特殊素材使用教程
十三、高分文章排版技巧
十四、公众号排版模板
十五、公众号运营
十六、微信图文模板
十七、新媒体运营
十八、会员常见问题
发布时间:2020-09-16 17:23:53
在微信AI背后,技术究竟如何让一切发生?关注微信AI公众号,我们将为你一一道来。今天我们将放送微信AI技术专题系列“微信看一看背后的技术架构详解”的第四篇——《深度强化学习在微信看一看推荐混排的应用》。
导语
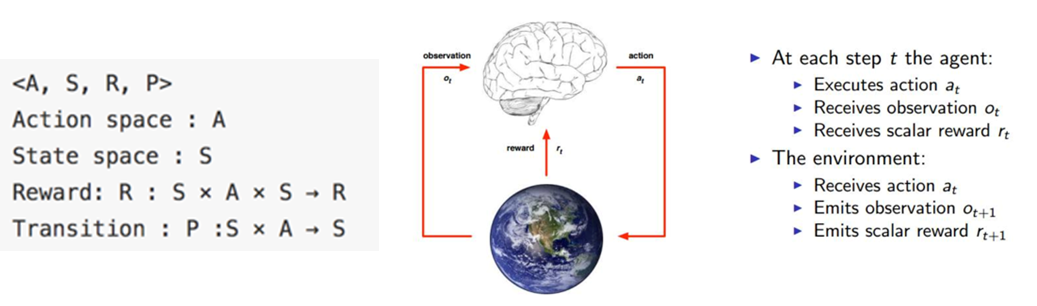
什么是强化学习
(1)基本概念
(2)与监督学习,非监督学习的区别

(3)Multi-armed bandit 多臂赌博机
(4)强化学习的算法和AlphaGo
(5)强化学习实践




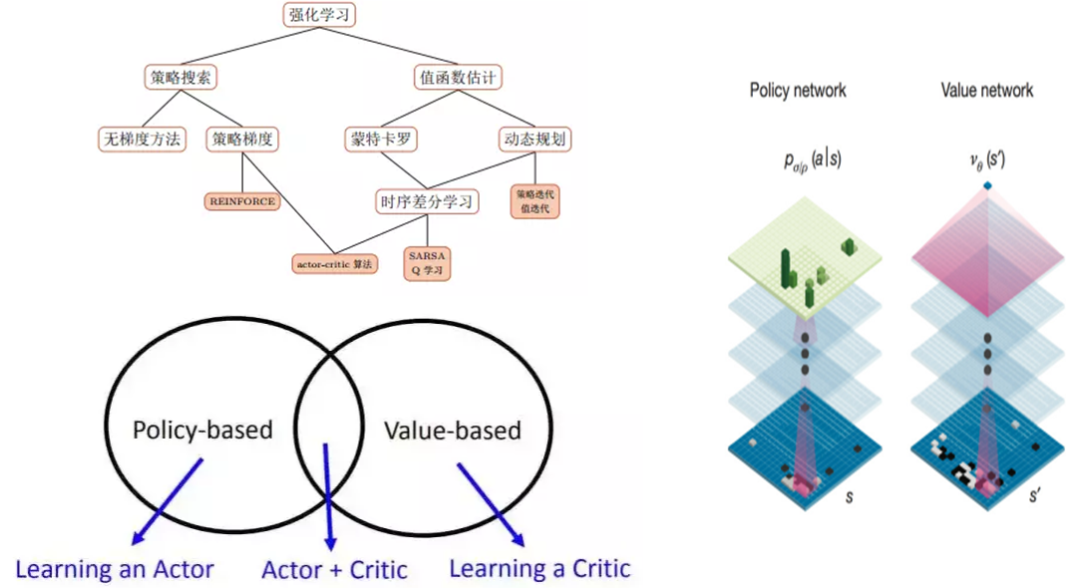
为什么用强化学习
(1)看一看混排
(2)统一的点击率预估排序
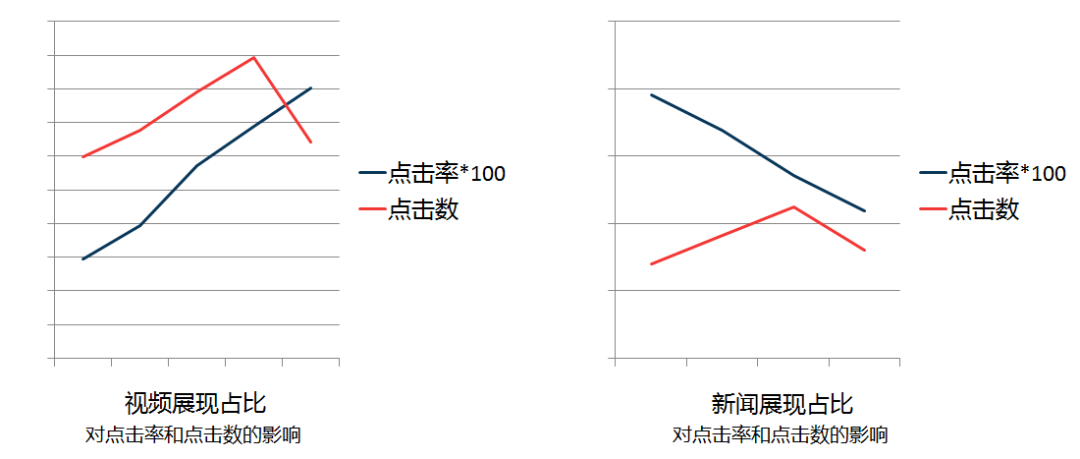
(3)强化学习的引入 - 优化长期收益
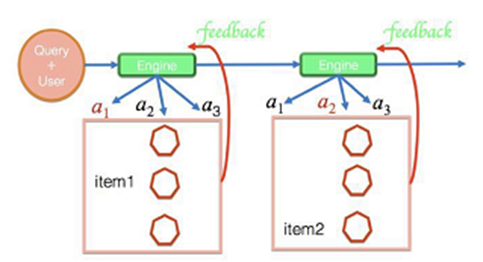
(4)强化学习的优势
混排三路召回,mp,video,news合并
Case
mp,video,video(0,1,1)
video,mp,mp(1,0,0)
video,video,video(1,0,0)
监督学习预测最优解是第三种,
选择点击率最大的。
强化学习预测最优解是第一种,
选择总收益最大的。
强化学习在看一看混排中的应用
(1)Session wise recommendation

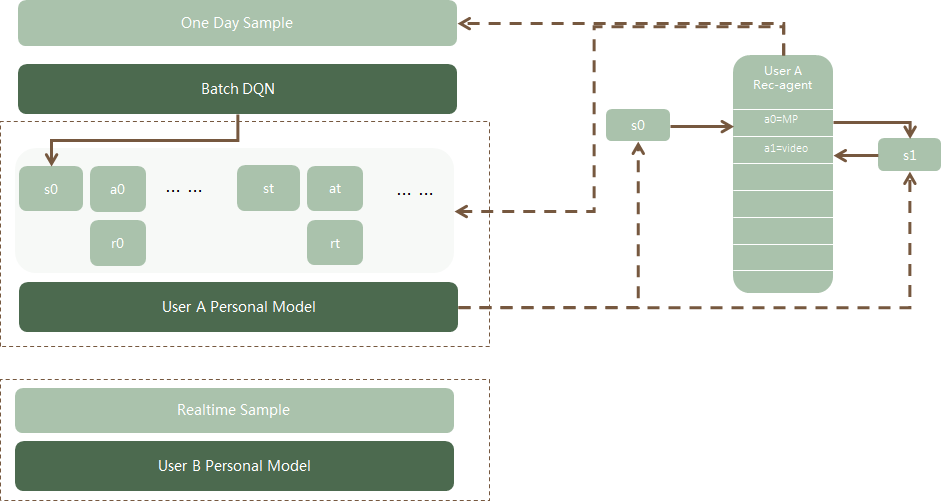
(2)Personal DQN
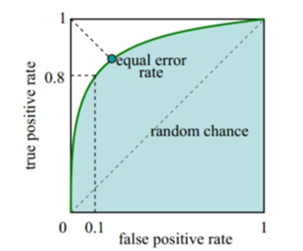
(3)离线评估 AUC?
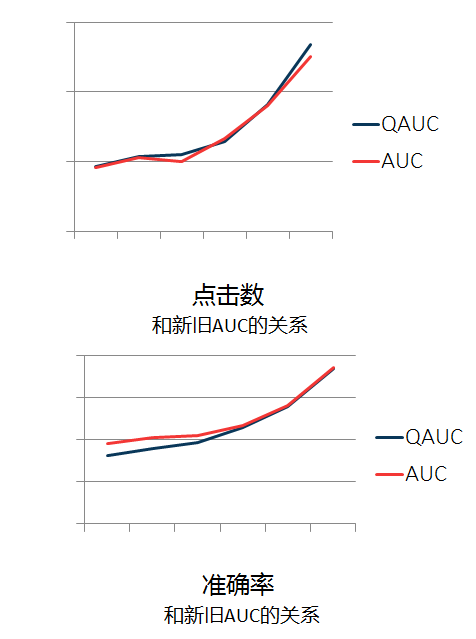
(4)线上效果
(5)模型优化
Session based recommendation
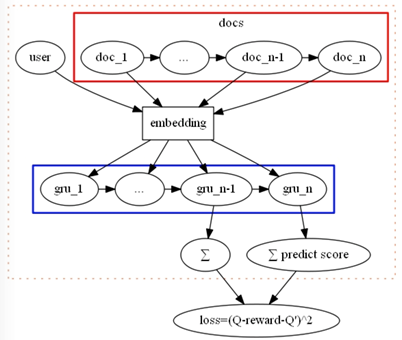
(6)模型优化
Bloom embedding & Dueling DQN
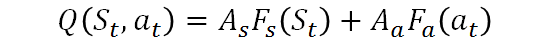
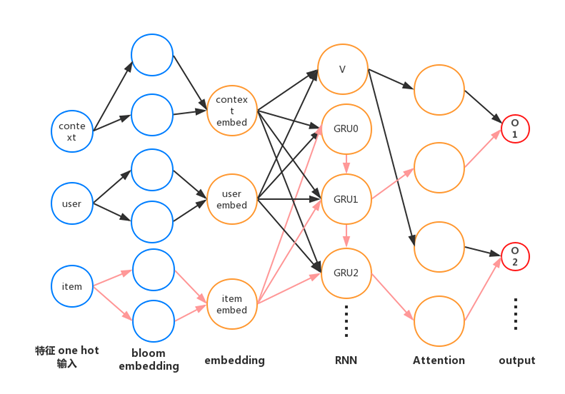
(7)模型优化Double DQN &
Dueling Double DQN (aka DDDQN)
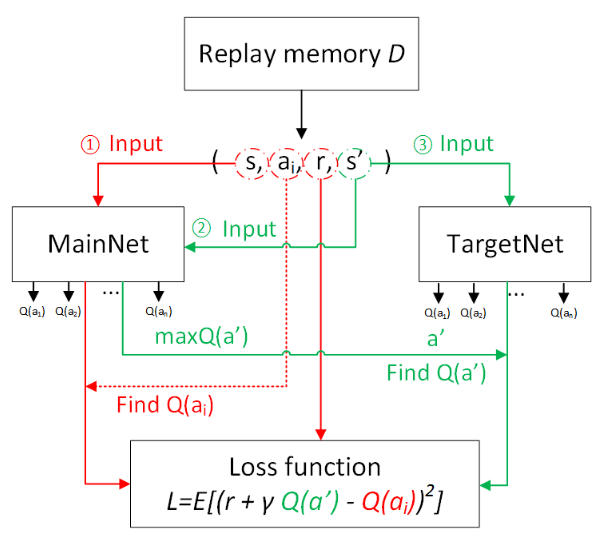
(8)负反馈 Reward & Focal loss
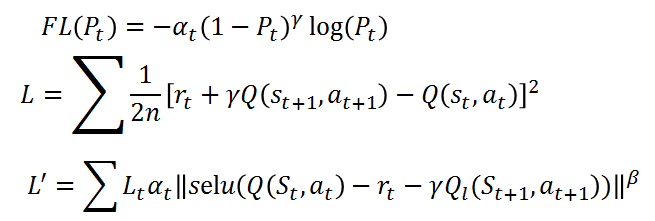
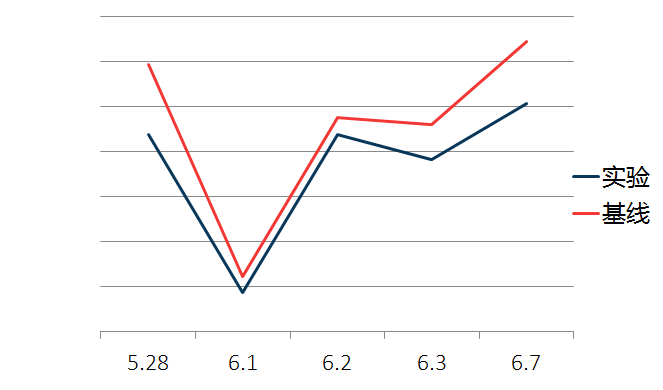
一些思考
AC 和 GAN
我也不是RL的专家,但我认为GAN是使用RL来解决生成建模问题的一种方式。GAN的不同之处在于,奖励函数对行为是完全已知和可微分的,奖励是非固定的,以及奖励是agent的策略的一个函数。但我认为GAN基本上可以说就是RL。
Ian Goodfellow(生成对抗网络之父)
注:此文章来源于微信AI;


微信在线客服
请提供详细的截图大图+文字说明您的问题。


微信扫码查看帮助
扫码关注,获取各种排版小技巧,黑科技!
Copyright © xmyeditor.com 2015-2025 河南九鲸网络科技有限公司
ICP备案号:豫ICP备16024496号-1 豫公网安备:41100202000215 经营许可证编号:豫B2-20250200 网信算备:410103846810501250019号



