
按【Ctrl+D】或拖动【 小墨鹰LOGO】到书签栏,收藏本站!
一、小墨鹰简介
二、新版视频教程
三、新手入门
四、微信公众号早报
五、手机版编辑器
六、功能详细介绍
七、基础排版技巧
八、常见问题解答
九、微信公众号扫盲
十、高级功能详细介绍
十一、进阶排版技巧
十二、特殊素材使用教程
十三、高分文章排版技巧
十四、公众号排版模板
十五、公众号运营
十六、微信图文模板
十七、新媒体运营
十八、会员常见问题
发布时间:2020-10-15 19:38:39
在微信AI背后,技术究竟如何让一切发生?关注微信AI公众号,我们将为你一一道来。今天我们将放送微信AI技术专题系列“微信看一看背后的技术架构详解”的第五篇——《微信看一看文章流行度预测算法》。
本文对微信看一看中爆款文章早期预测工作进行了简单介绍,目标是如何在文章发表的初期,识别出爆款文章。本文从问题定义,建模动机,模型设计,收集样本以及训练过程进行了详细的介绍。本项目的成果应用于看一看排序,新闻队列打分,文章离线打分等多个场景,核心算法以“Popularity Prediction on Online Articles with Deep Fusion of Temporal Process and Content Features”发表于AAAI2019会议上。
背景介绍
模型架构

时序过程建模


内容特征建模
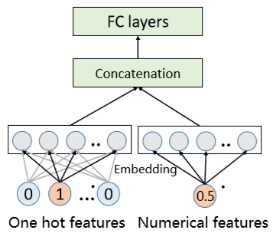
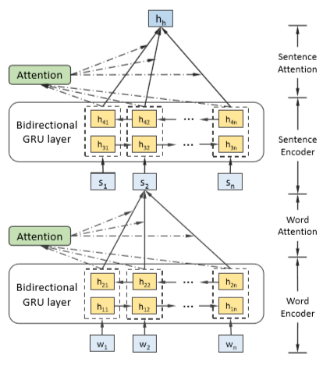
注意力融合模块
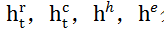 分别代表LSTM,CNN,HAN和元特征嵌入的输出。由于在网络文章发布后的最初阶段,时间过程模型很难学习流行度的整体增长趋势。因此,预测主要取决于内容特征建模。随着时间的推移,观察到的受欢迎程度越来越接近整体受欢迎程度,因此时间建模在预测中起主要作用。注意力融合机制正是将与灵活权重α相结合,α是和时间t的函数,因此它可以自动适应不同模块的输出,具有良好的处理时序过程动态演化的灵活性。注意力机制是逐元素组合,这里将馈入全连接层以进行特征组合,并获得各元素的对齐向量
分别代表LSTM,CNN,HAN和元特征嵌入的输出。由于在网络文章发布后的最初阶段,时间过程模型很难学习流行度的整体增长趋势。因此,预测主要取决于内容特征建模。随着时间的推移,观察到的受欢迎程度越来越接近整体受欢迎程度,因此时间建模在预测中起主要作用。注意力融合机制正是将与灵活权重α相结合,α是和时间t的函数,因此它可以自动适应不同模块的输出,具有良好的处理时序过程动态演化的灵活性。注意力机制是逐元素组合,这里将馈入全连接层以进行特征组合,并获得各元素的对齐向量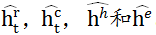 。然后使用一个两层的神经网络计算注意力权重αm,计算方式如下:
。然后使用一个两层的神经网络计算注意力权重αm,计算方式如下: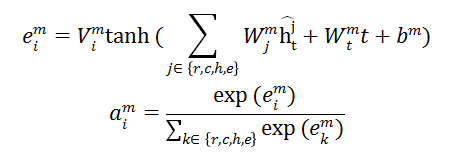
 。然后将最大概率对应的流行度类别作为最终的预测结果。具体计算过程如下:
。然后将最大概率对应的流行度类别作为最终的预测结果。具体计算过程如下: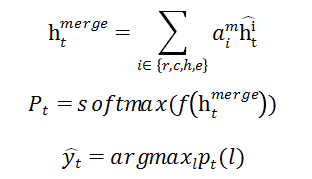
模型训练
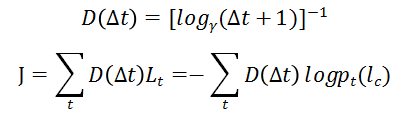
实 验
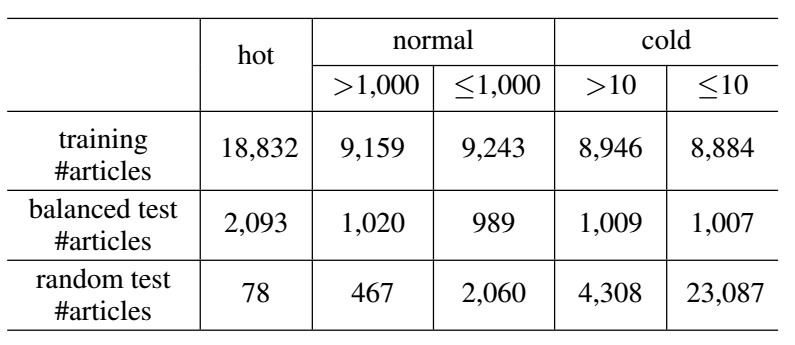
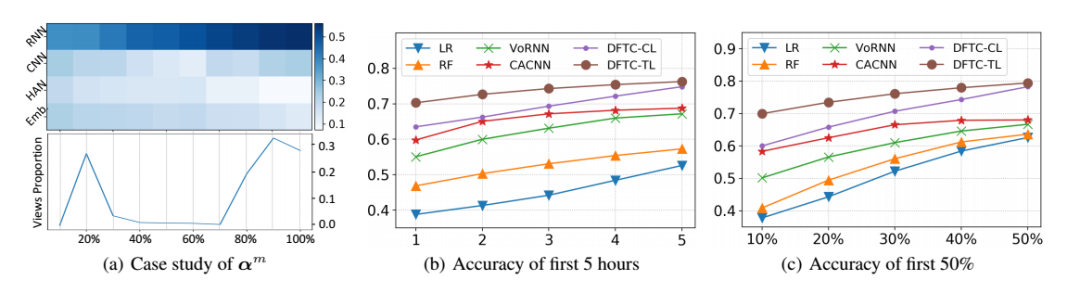
经验和思考
通过以上几点的结合,模型在预测在线文章的流行度时对时序过程和内容特征进行了深度融合建模,两者优势互补,可以在在线文章发布后生命周期的早期较好预测其流行度。
微信AI
不描摹技术的酷炫,不依赖拟人的形态,微信AI是什么?是悄无声息却无处不在,是用技术创造更高效率,是更懂你。
微信AI关注语音识别与合成、自然语言处理、计算机视觉、工业级推荐系统等领域,成果对内应用于微信翻译、微信视频号、微信看一看等业务,对外服务王者荣耀、QQ音乐等产品。
注:此文章来源于微信AI;


微信在线客服
请提供详细的截图大图+文字说明您的问题。


微信扫码查看帮助
扫码关注,获取各种排版小技巧,黑科技!
Copyright © xmyeditor.com 2015-2025 河南九鲸网络科技有限公司
ICP备案号:豫ICP备16024496号-1 豫公网安备:41100202000215 经营许可证编号:豫B2-20250200 网信算备:410103846810501250019号



